[Go로 구현하는 블록체인] Part 6: 트랜잭션 2
Jun 14, 2018 00:00 · 6390 words · 13 minute read
Building Blockchain in Go 시리즈를 번역한 글입니다.
서론
시리즈 초반부에 필자는 블록체인은 분산된 데이터베이스라고 말한 적이 있다. 우리는 지금까지 “분산” 부분은 건너뛰고 “데이터베이스” 부분에 집중했었다. 또한 여태 블록체인 데이터베이스를 이루는 대부분의 것들을 구현해왔다. 이 파트에서는 이전 파트에서 건너뛴 메커니즘들을 다루고, 다음 파트에서는 블록체인의 분산된 특성에 대해 다뤄볼 것이다.
이전 파트들:
이 파트에서는 중요한 코드 변경사항을 소개하기 때문에 모든 코드를 설명하는건 의미가 없다. 모든 변경사항은 여기를 참조하라.
보상
이전 글에서 생략한 것중 하나는 바로 채굴에 대한 보상이다. 우리는 보상을 구현하기 위해 필요한 모든것들을 이미 구현했다.
보상은 단순히 코인베이스 트랜잭션일뿐이다. 노드를 채굴하면 새로운 블록의 채굴이 시작되고, 큐에 있는 트랜잭션을 가져와 그 앞에 코인베이스 트랜잭션을 붙인다. 코인베이스 트랜잭션의 유일한 출력에는 채굴자의 공개키 해시가 포함된다.
보상 구현은 send 커맨드를 수정하는 정도로 아주 쉽다.
func (cli *CLI) send(from, to string, amount int) {
...
bc := NewBlockchain()
UTXOSet := UTXOSet{bc}
defer bc.db.Close()
tx := NewUTXOTransaction(from, to, amount, &UTXOSet)
cbTx := NewCoinbaseTX(from, "")
txs := []*Transaction{cbTx, tx}
newBlock := bc.MineBlock(txs)
fmt.Println("Success!")
}
우리가 구현한 블록체인에선 트랜잭션을 생성한 사람이 새로운 블록을 채굴하고 보상을 받는다.
UTXO 집합
Part 3. 영속성 및 CLI에서는 비트코인 코어가 데이터베이스에 블록을 저장하는 방법에 대해 알아보았다. 블록들은 blocks 데이터베이스에, 트랜잭션 출력은 chainstate 데이터베이스에 저장된다고 했었다. chainstate의 구조를 다시 한 번 살펴보자.
- ‘c’ + 32바이트 트랜잭션 해시 -> 해당 트랜잭션에 대한 미사용 트랜잭션 출력 레코드
- ‘B’ -> 32바이트 블록 해시: 데이터베이스가 미사용 트랜잭션 출력을 나타내는 블록 해시
우리는 이미 트랜잭션을 구현했지만, 출력을 저장하기 위해 chainstate를 사용하지 않았다. 이것이 지금 우리가 하려는 것이다.
chainstate는 트랜잭션을 저장하지 않는다. 대신 UTXO 집합 또는 미사용 트랜잭션 출력의 집합을 저장한다. 이 외에도 “데이터베이스가 미사용 트랜잭션 출력을 나타내는 블록 해시"를 저장하지만, 우리는 지금 블록 높이를 사용하고 있지 않기 때문에 이 부분은 생략할 것이다. (다음 파트에서 구현한다)
그렇다면 UTXO 집합은 왜 저장하려는걸까?
이전에 구현했던 Blockchain.FindUnspentTransactions 메서드를 생각해보자.
func (bc *Blockchain) FindUnspentTransactions(pubKeyHash []byte) []Transaction {
...
bci := bc.Iterator()
for {
block := bci.Next()
for tx := range block.Transactions {
...
}
if len(block.PrevBlockHash) == 0 {
break
}
}
}
이 함수는 미사용 출력을 갖는 트랜잭션을 검색한다. 트랜잭션은 블록에 저장되어 있기 때문에 블록체인의 블록들을 순회하면서 블록 안에 있는 모든 트랜잭션을 확인한다. 2017년 9월 18일 기준으로 비트코인에는 485,860개의 블록들이 있으며 전체 데이터베이스의 크기는 약 140+ Gb에 달한다. 이는 트랜잭션 검증을 위해선 모든 노드를 실행시켜야함을 의미한다. 게다가 트랜잭션 검증은 많은 블록을 순회해야할 수도 있다.
이 문제에 대한 해결책은 미사용 출력만을 저장하는 인덱스를 만드는 것이다. 이게 바로 UTXO 집합이 필요한 이유이다. 이는 모든 블록체인 트랜잭션으로부터 만들어진 캐시인 셈이다 (물론 처음에는 블록들을 순회해야하지만, 이는 딱 한 번만 이루어진다). 그리고 이 인덱스는 나중에 잔고 계산 및 새로운 트랜잭션의 검증에서도 사용된다. UTXO 집합은 2017년 9월 기준으로 약 2.7 Gb정도 된다.
이제 UTXO 집합을 구현하기 위해 어떤걸 수정해야할지 생각해보자. 현재 우리는 트랜잭션 검색을 위해 다음 메서드들을 사용하고 있다.
- Blockchain.FindUnspentTransactions - 미사용 출력을 가진 트랜잭션을 검색하는 주요 함수. 모든 블록에 대한 순회가 일어나는 곳.
- Blockchain.FindSpendableOutputs - 새로운 트랜잭션이 생성될 때 사용되는 함수. 필요한 수량을 채울 수 있을만큼의 출력을 검색. Blockchain.FindUnspentTransactions를 사용한다.
- Blockchain.FindUTXO - 주어진 공개키 해시에 대 한 미사용 출력을 검색하며 잔고를 계산할 때 사용됨. Blockchain.FindUnspentTransactions를 사용한다.
- Blockchain.FindTransaction - ID로 블록체인에서 트랜잭션을 검색. 찾을 때까지 모든 블록을 순회한다.
보다시피, 모든 메서드가 데이터베이스상의 모든 블록을 순회하고 있다. 하지만 지금은 UTXO 집합이 모든 트랜잭션을 저장하고 있지는 않기 때문에 위의 모든 메서드들을 개선할 수는 없고 미사용 출력을 사용하는 메서드만 개선이 가능하다. 따라서 Blockchain.FindTransaction는 예외로 한다.
우리는 이제 다음 메서드들을 구현할 것이다.
- Blockchain.FindUTXO - 블록들을 순회하면서 모든 미사용 출력들을 검색한다.
- UTXOSet.Reindex - 미사용 출력을 찾기 위해 FindUTXO를 사용하며 검색 결과를 데이터베이스에 저장한다. 캐싱이 발생하는 곳이다.
- UTXOSet.FindSpendableOutputs - Blockchain.FindSpendableOutputs과 유사하나 UTXO 집합을 사용한다.
- Blockchain.FindTransaction - 기존과 동일하다.
가장 많이 사용되는 두 함수는 지금부터 캐시를 사용할 것이다. 이제 코드를 작성해보자.
type UTXOSet struct {
Blockchain *Blockchain
}
우리는 단일 데이터베이스를 사용할거지만 UTXO 집합은 다른 버킷에 저장할 것이다. UTXOSet은 Blockchain과 결합되어 있다.
func (u UTXOSet) Reindex() {
db := u.Blockchain.db
bucketName := []byte(utxoBucket)
err := db.Update(func(tx *bolt.Tx) error {
err := tx.DeleteBucket(bucketName)
_, err = tx.CreateBucket(bucketName)
})
UTXO := u.Blockchain.FindUTXO()
err = db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket(bucketName)
for txID, outs := range UTXO {
key, err := hex.DecodeString(txID)
err = b.Put(key, outs.Serialize())
}
})
}
이 메서드는 처음에 UTXO 집합을 생성한다. 버킷이 이미 존재하면 삭제후, 블록체인에서 모든 미사용 출력을 가져와 버킷에 저장한다.
Blockchain.FindUTXO는 Blockchain.FindUnspentTransactions와 거의 유사하나 이 메서드는 트랜잭션 아이디 -> 트랜잭션 출력 쌍들의 맵을 반환한다.
이제 UTXO 집합을 사용해 코인을 전송할 수 있다.
func (u UTXOSet) FindSpendableOutputs(pubKeyHash []byte, amount int) (int, map[string][]int) {
unspentOutputs := make(map[string][]int)
accumulated := 0
db := u.Blockchain.db
err := db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(utxoBucket))
c := b.Cursor()
for k, v := c.First(); k != nil; k, v = c.Next() {
txID := hex.EncodeToString(k)
outs := DeserializeOutputs(v)
for outIdx, out := outs.Outputs {
if out.IsLockedWithKey(pubKeyHash) && accumulated < amount {
accumulated += out.Value
unspentOutputs[txID] = append(unspentOutputs[txID], outIdx)
}
}
}
})
return accumulated, unspentOutputs
}
또는 잔고를 확인할 수도 있다.
func (u UTXOSet) FindUTXO(pubKeyHash []byte) []TXOutput {
var UTXOs []TXOutput
db := u.Blockchain.db
err := db.View(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(utxoBucket))
c := b.Cursor()
for k, v := c.First(); k != nil; k, v = c.Next() {
outs := DeserializeOutputs(v)
for _, out := range outs.Outputs {
if out.IsLockedWithKey(pubKeyHash) {
UTXOs = append(UTXOs, out)
}
}
}
return nil
})
return UTXOs
}
이들은 대응되는 Blockchain 메서드들의 약간 수정된 버전이다. Blockchain의 해당 메서드들은 더이상 필요없다.
UTXO 집합을 따로 둔다는건 트랜잭션 데이터가 두 개의 저장소로 나뉘어졌음을 의미한다. 실제 트랜잭션은 블록체인에 저장되고, 미사용 출력은 UTXO 집합에 저장된다. 이러한 분리에는 견고한 동기화 메커니즘이 필요한데 UTXO 집합을 항상 업데이트하고 최신 트랜잭션의 출력도 저장해야하기 때문이다. 그러나 빈번한 블록체인 스캔은 피하고싶기 때문에 새로운 블록이 채굴될 때마다 재색인을 하고싶지는 않다. 따라서 UTXO 집합을 업데이트하는 메커니즘이 필요하다.
func (u UTXOSet) Update(block *Block) {
db := u.Blockchain.db
err := db.Update(func(tx *bolt.Tx) error {
b := tx.Bucket([]byte(utxoBucket))
for _, tx := range block.Transactions {
if tx.IsCoinbase() == false {
for _, vin := range tx.Vin {
updatedOuts := TXOutputs{}
outsBytes := b.Get(vin.Txid)
outs := DeserializeOutputs(outsBytes)
for outIdx, out := range outs.Outputs {
if outIdx != vin.Vout {
updatedOuts.Outputs = append(updatedOuts.Outputs, out)
}
}
if len(updatedOuts.Outputs) == 0 {
err := b.Delete(vin.Txid)
} else {
err := b.Put(vin.Txid, updatedOuts.Serialize())
}
}
}
newOutputs := TXOutputs{}
for _, out := range tx.Vout {
newOutputs.Outputs = append(newOutputs.Outputs, out)
}
err := b.Put(tx.ID, newOutputs.Serialize())
}
})
}
복잡해보이지만 직관적인 코드이다. 새로운 블록이 채굴되면 UTXO 집합은 갱신되어야한다. 갱신이란 사용된 출력을 제거하고 새로 채굴된 트랜잭션의 미사용 출력을 추가하는 것을 의미한다. 어떤 트랜잭션의 출력이 모두 제거되고 더 이상의 미사용 출력이 없다면 트랜잭션은 제거된다.
이제 필요한 곳에서 UTXO 집합을 사용해보자.
func (cli *CLI) createBlockchain(address string) {
...
bc := CreateBlockchain(address)
defer bc.db.Close()
UTXOSet := UTXOSet{bc}
UTXOSet.Reindex()
...
}
재색인은 새로운 블록체인이 생성된 직후에 수행된다. 지금은 이 메서드가 Reindex가 사용되는 유일한 위치이다. 블록체인의 초반에는 하나의 트랜잭션만을 갖는 하나의 블록밖에 없기 때문에 재색인을 사용하는건 과해보이고 대신 Update를 사용할 수도 있으나, 나중에 가면 재색인 메커니즘이 필요할 것이다.
func (cli *CLI) send(from, to string, amount int) {
...
NewBlock := bc.MineBlock(txs)
UTXOSet.Update(newBlock)
}
그리고 UTXO 집합은 새로운 블록이 채굴되면 갱신된다.
잘 동작하는지 확인해보자.
$ blockchain_go createblockchain -address 1JnMDSqVoHi4TEFXNw5wJ8skPsPf4LHkQ1
00000086a725e18ed7e9e06f1051651a4fc46a315a9d298e59e57aeacbe0bf73
Done!
$ blockchain_go send -from 1JnMDSqVoHi4TEFXNw5wJ8skPsPf4LHkQ1 -to 12DkLzLQ4B3gnQt62EPRJGZ38n3zF4Hzt5 -amount 6
0000001f75cb3a5033aeecbf6a8d378e15b25d026fb0a665c7721a5bb0faa21b
Success!
$ blockchain_go send -from 1JnMDSqVoHi4TEFXNw5wJ8skPsPf4LHkQ1 -to 12ncZhA5mFTTnTmHq1aTPYBri4jAK8TacL -amount 4
000000cc51e665d53c78af5e65774a72fc7b864140a8224bf4e7709d8e0fa433
Success!
$ blockchain_go getbalance -address 1JnMDSqVoHi4TEFXNw5wJ8skPsPf4LHkQ1
Balance of '1F4MbuqjcuJGymjcuYQMUVYB37AWKkSLif': 20
$ blockchain_go getbalance -address 12DkLzLQ4B3gnQt62EPRJGZ38n3zF4Hzt5
Balance of '1XWu6nitBWe6J6v6MXmd5rhdP7dZsExbx': 6
$ blockchain_go getbalance -address 12ncZhA5mFTTnTmHq1aTPYBri4jAK8TacL
Balance of '13UASQpCR8Nr41PojH8Bz4K6cmTCqweskL': 4
잘 동작한다! 1JnMDSqVoHi4TEFXNw5wJ8skPsPf4LHkQ1 주소의 소유자는 총 3번의 보상을 받았다.
- 제네시스 블록 채굴시
- 0000001f75cb3a5033aeecbf6a8d378e15b25d026fb0a665c7721a5bb0faa21b 블록 채굴시
- 000000cc51e665d53c78af5e65774a72fc7b864140a8224bf4e7709d8e0fa433 블록 채굴시
머클트리
이 파트에서 다루고자하는 또 하나의 최적화 메커니즘이 있다.
이전에도 언급했듯이, 전체 비트코인 데이터베이스 (블록체인)의 크기는 140 Gb를 웃돈다. 비트코인의 분산된 특성 때문에 네트워크 상의 모든 노드는 독립적이고 자체적이어야 한다. 즉, 모든 노드는 블록체인의 전체 복사본을 가지고 있어야한다. 많은 사람들이 비트코인을 사용하기 시작하면서 이 규칙은 이행하기가 어려워졌다. 모든 사람이 전체 노드를 실행하지는 않는다. 또한 노드들은 네트워크의 자격있는 참여자이므로 트랜잭션과 블록을 검증해야한다는 책임이 있다. 그리고 다른 노드와 상호 작용하고 새로운 블록을 다운로드하기 위해 필요한 특정 인터넷 트래픽이 필요하다.
사토시 나카모토가 발행한 비트코인 논문의 원문에서는 이 문제를 해결하기 위한 간소화된 지불 검증 (Simplified Payment Verification, SPV)이라는 해결책을 제시하고 있다. SPV는 전체 블록체인을 다운로드 받지 않으며 블록과 트랜잭션을 검증하지 않는 가벼운 비트코인 노드이다. 대신 이는 지불 검증을 위해 블록에서 트랜잭션을 검색하고 꼭 필요한 데이터를 얻기 위해 전체 노드와 연결된다. 이 메커니즘을 사용하면 하나의 전체 노드를 실행하면서 여러개의 경량 노드를 사용할 수 있다.
SPV가 가능하려면 전체 블록을 다운로드 받지 않고도 어떤 블록이 특정 트랜잭션을 포함하고 있는지 확인할 수 있는 방법이 필요하다. 머클트리를 사용할 때가 왔다.
머클트리는 비트코인에서 트랜잭션 해시를 얻기 위해 사용되며, 블록 헤더에 저장되고 작업 증명 시스템에서 고려된다. 지금까지 우리는 단순히 한 블록의 각 트랜잭션의 해시를 이어붙여 SHA-256 알고리즘을 적용해왔다. 물론 이 방식도 블록 트랜잭션들의 유일한 표현값을 얻기 위한 좋은 방식이지만, 머클트리의 이점을 지니고 있지는 않다.
그럼 이제 머클트리에 대해서 살펴보자.
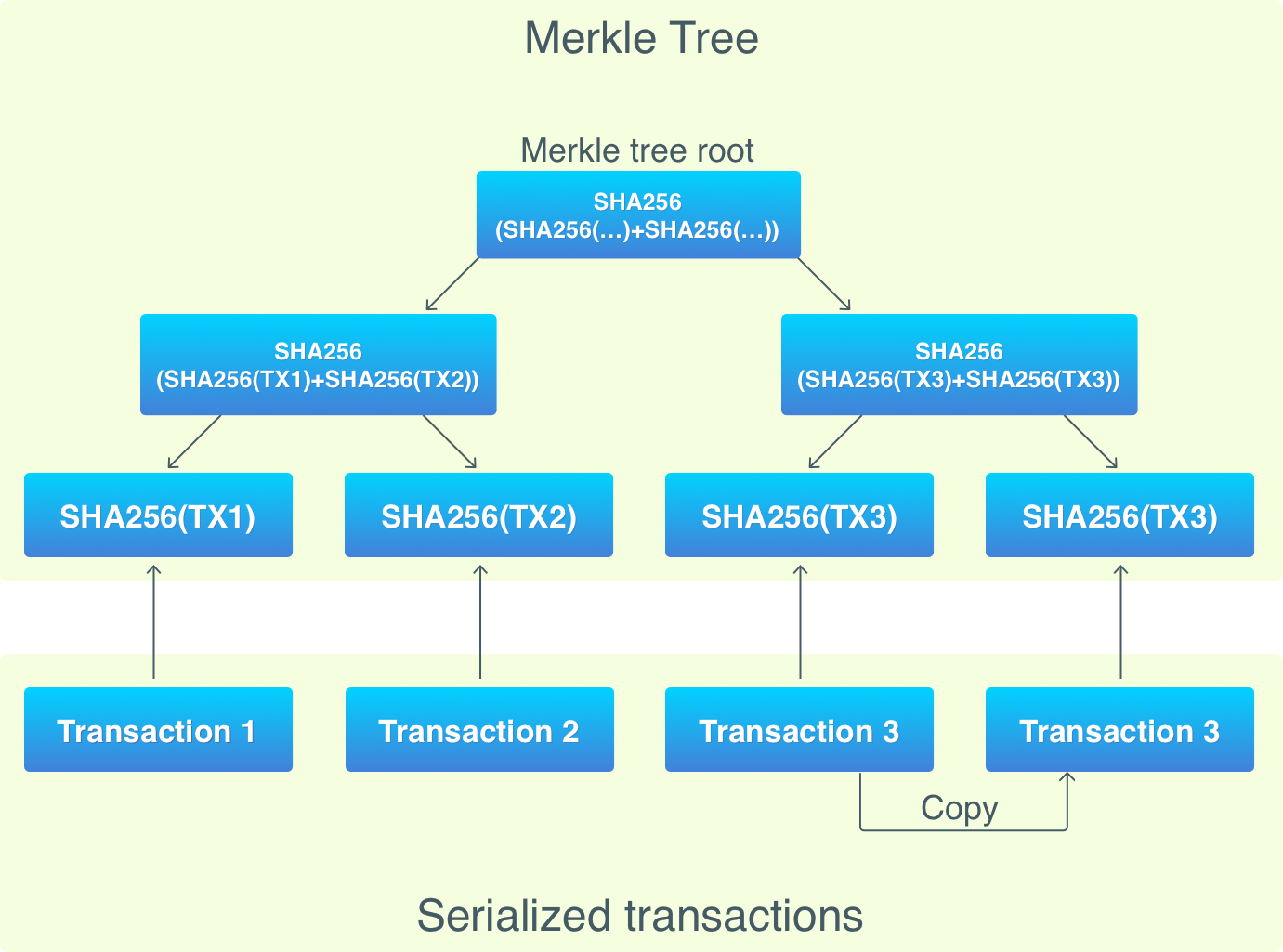
머클트리는 각 블록마다 생성되며, 트랜잭션 해시 (비트코인은 이중 SHA256 해싱을 사용함)가 저장된 리프 (트리의 바닥)로부터 시작된다. 리프의 개수는 반드시 짝수여야만 하지만, 모든 블록이 짝수개의 트랜잭션을 가지고 있지는 않다. 트랜잭션의 개수가 홀수개인 경우, 마지막 트랜잭션이 중복되어 들어간다 (머클트리에만 중복되어 들어가며 블록에 실제로 중복된 트랜잭션이 들어가지는 않음).
아래에서 위로 올라가면서 리프들은 쌍으로 그룹핑된다. 해시는 하나로 연결되며, 연결된 해시값으로부터 새로운 해시를 얻는다. 새로운 해시는 두 트리 노드의 해시로 구성된다. 이 과정은 트리의 루트 노드라고 불리는 단일 노드에 도달할때까지 반복된다.
루트 해시는 트랜잭션들의 유일한 표현값으로 사용되며 블록 헤더에 저장되어 작업 증명 시스템에서 사용된다.
머클트리의 이점은 노드가 전체 블록을 다운로드 받지 않고도 특정 트랜잭션의 포함 여부를 검증할 수 있다는 것이다. 검증 작업에는 트랜잭션의 해시와 머클트리의 루트 해시 그리고 머클 경로만 있으면 된다.
이제 코드를 한 번 작성해보자.
type MerkleTree struct {
RootNode *MerkleNode
}
type MerkleNode struct {
Left *MerkleNode
Right *MerkleNode
Data []byte
}
구조체부터 작성한다. 모든 MerkleNode는 데이터를 가지며 브랜치 (Left/Right)로 연결된다. MerkleTree는 실제로 다음 노드와 연결되어 있는 루트 노드이며, 노드들은 다른 노드와 차례대로 연결된다.
먼저 새로운 노드를 생성해보자.
func NewMerkleNode(left, right *MerkleNode, data []byte) *MerkleNode {
mNode := MerkleNode{}
if left == nil && right == nil {
hash := sha256.Sum256(data)
mNode.Data = hash[:]
} else {
prevHashes := append(left.Data, right.Data...)
hash := sha256.Sum256(prevHashes)
mNode.Data = hash[:]
}
mNode.left = left
mNode.right = right
return &mNode
}
모든 노드는 데이터를 가진다. 노드가 리프이면 데이터는 외부에서 전달된다 (우리의 경우 직렬화된 트랜잭션이 외부 데이터에 해당한다). 노드가 다른 노드와 연결되어 있으면, 연결된 노드의 데이터를 가져와 합친 뒤 해싱한다.
func NewMerkleTree(data [][]byte) *MerkleTree {
var nodes []MerkleNode
if len(data)%2 != 0 {
data = append(data, data[len(data)-1])
}
for _, datum := range data {
node := NewMerkleNode(nil, nil, datum)
nodes = append(nodes, *node)
}
for i := 0; i < len(data)/2; i++ {
var newLevel []MerkleNode
for j := 0; j < len(nodes); j += 2 {
node := NewMerkleNode(&nodes[j], *nodes[j+1], nil)
newLevel = append(newLevel, *node)
}
nodes = newLevel
}
mTree := MerkleTree{&nodes[0]}
return &mTree
}
새 트리가 생성될 때 가장 먼저 확인 해야할 일은 리프의 개수가 짝수개인지 확인하는 것이다. 그 다음엔 data (직렬화된 트랜잭션의 배열)를 트리의 리프로 변환한 뒤 리프로부터 트리를 만들어나간다.
이제 작업 증명 시스템에서 트랜잭션 해시를 얻는데 사용되는 Block.HashTransactions를 수정해보자.
func (b *Block) HashTransactions() []byte {
var transactions [][]byte
for _, tx := range b.Transactions {
transactions = append(transactions, tx.Serialize())
}
mTree := NewMerkleTree(transactions)
return mTree.RootNode.Data
}
트랜잭션은 먼저 직렬화된 다음 (encoding/gob을 사용) 머클트리를 만드는데 사용된다. 트리의 루트는 블록 트랜잭션들의 식별자로 사용된다.
P2PKH
좀 더 자세히 다루고자하는 주제가 하나 더 있다.
여러분도 기억하겠지만, 비트코인에는 트랜잭션 출력을 잠그고 트랜잭션 입력이 출력을 해제하기 위한 데이터를 제공하는데 사용되는 Script라는 프로그래밍 언어가 있다. 이 언어는 단순하며 코드는 단순히 데이터와 연산자의 시퀀스로 이루어져있다. 예제를 하나 보자.
5 2 OP_ADD 7 OP_EQUAL
5, 2 그리고 7이 데이터이고, OP_ADD와 OP_EQUAL이 연산자이다. Script 코드는 좌에서 우로 실행된다. 모든 데이터를 스택에 넣고 다음 연산자를 스택의 맨위 원소에 적용한다. Script의 스택은 단순한 FILO (First Input Last Output) 메모리 스토리지로 스택의 첫번째 원소는 가장 마지막에 사용되고 모든 나중에 들어온 원소는 이전 원소 위에 추가된다.
위 스크립트의 실행을 단계별로 살펴보자.
- 스택: 비어있음. 스크립트: 5 2 OP_ADD 7 OP_EQUAL
- 스택: 5. 스크립트: 2 OP_ADD 7 OP_EQUAL
- 스택: 5 2. 스크립트: OP_ADD 7 OP_EQUAL
- 스택: 7. 스크립트: 7 OP_EQUAL
- 스택: 7 7. 스크립트: OP_EQUAL
- 스택: true. 스크립트: 비어있음.
OP_ADD는 스택에서 두 개의 원소를 취해 합한 다음 그 합을 스택에 넣는다. OP_EQUAL은 스택에서 두 원소를 취해 비교한 다음 같으면 true를, 아니면 false를 스택에 넣는다. 스크립트 실행 결과는 스택의 맨위 원소의 값이된다. 위 예제의 경우 true가 실행 결과가 되며 스크립트가 성공적으로 수행되었음을 알 수 있다.
그럼 이제 비트코인에서 지불을 수행하기 위해 사용되는 스크립트를 살펴보자.
<signature> <pubKey> OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG
이 스크립트를 *Pay to Public Key Hash (P2PKH)*라고 부르며 비트코인에서 가장 흔하게 사용되는 스크립트이다. 이는 말그대로 공개키 해시를 지불한다 (특정한 공개키로 코인을 잠금). 이게 바로 비트코인 결제의 핵심이다. 계좌도 없고 계좌간 송금도 없다. 그저 제공된 서명과 공개키가 올바른지를 확인하는 스크립트만 있을뿐이다.
위 스크립트는 실제로 두 부분으로 나뉘어 저장된다.
- 앞 부분의 **<signature> <pubKey>**는 입력의 ScriptSig 필드에 저장된다.
- 뒷 부분의 OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG는 입력의 ScriptPubKey에 저장된다.
따라서 출력은 로직 해제를 정의하고 입력은 출력 해제를 위한 데이터를 제공하는 것이다. 스크립트를 실행해보자.
- 스택: 비어있음. 스크립트: <signature> <pubKey> OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature>. 스크립트: <pubKey> OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature> <pubKey>. 스크립트: OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature> <pubKey> <pubKey>. 스크립트: OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature> <pubKey> <pubKeyHash>. 스크립트: <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature> <pubKey> <pubKeyHash> <pubKeyHash>. 스크립트: OP_EQUALVERIFY OP_CHECKSIG.
- 스택: <signature> <pubKey>. 스크립트: OP_CHECKSIG.
- 스택: true 또는 false. 스크립트: 비어있음.
OP_DUP은 최상위 스택 원소를 복제한다. OP_HASH160은 최상위 스택 원소를 가져와 RIPEMD160으로 해싱한다. 해싱 결과는 스택에 저장된다. OP_EQUALVERIFY는 스택의 두 최상위 원소를 비교하며, 만약 같지 않으면 스크립트에 인터럽트를 건다. OP_CHECKSIG는 트랜잭션을 해싱하고 **<signature>**와 **<pubKey>**를 사용해 트랜잭션의 서명을 검증한다. 마지막 연산자는 아주 복잡한데, 이는 트랜잭션의 잘려진 복사본을 만들어 해싱한 뒤 (이 해시가 서명된 트랜잭션의 해시이므로), **<signature>**와 **<pubKey>**를 사용해 서명이 올바른지 검사한다.
이러한 스크립팅 언어를 사용하면 비트코인을 스마트 컨트랙트 플랫폼으로도 사용할 수 있다. 예를 들어, 스크립팅 언어를 사용해 단일키 전송 방법 외에 다른 지불 방법을 구현할 수도 있다.
결론
이제 거의 끝났다! 우리는 블록체인 기반 암호화의 거의 모든 핵심 기능들을 구현했다. 그리고 이제 블록체인, 주소, 채굴 그리고 트랜잭션을 갖게되었다. 그러나 이러한 메커니즘들에 생명을 불어넣고 비트코인을 글로벌 시스템으로 만든 또 하나의 기능이 있다. 바로 합의 (consensus)이다. 다음 파트에서는 블록체인의 “분산” 부분을 구현해보도록 하겠다.