[Go로 구현하는 블록체인] Part 2: 작업 증명
May 18, 2018 00:00 · 3549 words · 8 minute read
Building Blockchain in Go 시리즈를 번역한 글입니다.
서론
이전 파트에서 블록체인 데이터베이스의 핵심인 매우 간단한 데이터 구조를 만들어보았다. 그리고 각 블록을 이전 블록에 연결함으로써 체인에 블록을 추가할 수 있도록 만들었다. 하지만 우리가 구현한 블록체인 구현체에는 심각한 결함이 하나 있는데 바로 체인에 새 블록을 추가하기가 쉬우며 비용이 낮다는 것이다. 블록체인과 비트코인의 핵심은 새 블록을 추가하는 작업이 어렵다는 것이다. 이번 파트에서는 이 결함을 개선해보도록 하자.
작업 증명 (Proof of Work)
블록체인의 핵심 아이디어는 데이터를 추가하기 위해선 어떤 어려운 작업을 수행해야 한다는 것이다. 이 작업이 블록체인을 안전하고 일관성있게 만들어준다. 또한 이 어려운 작업을 수행한 참여자에게는 보상이 주어진다 (사람들이 채굴을 통해 코인을 얻는 방식이다).
이 메커니즘은 실생활과 아주 흡사한데 보상을 받으며 생계를 유지하기위해 열심히 일을 하는것과 유사하다. 블록체인에서 네트워크의 일부 참여자들 (채굴자)은 네트워크를 유지하기 위해 블록을 생성하고 이에 대한 보상을 받는다. 이 작업의 결과로 블록은 블록체인에 안전하게 추가되어 전체 블록체인 데이터베이스의 안정성을 유지한다. 작업을 마친 사람이 이 작업을 증명해야 한다는것에 주목할 필요가 있다.
“어려운 작업을 수행하고 이를 증명한다"의 전체 메커니즘을 작업 증명 (Proof of Work, PoW)이라고 부른다. 이는 엄청난 컴퓨팅 파워를 요구하기 때문에 작업이 무거우며 고성능 컴퓨터에서조차 빠르게 수행하기 어렵다. 또한, 블록 생성 속도를 시간당 약 6 블록으로 유지하기 위해 작업의 난이도는 시간이 지남에따라 증가한다. 비트코인에서 이 작업의 목표는 특정 요구사항을 충족하는 블록의 해시를 찾는 것이다. 그리고 이 해시가 증명 역할을 하기 때문에 증명을 찾는 작업이 실질적인 작업이다.
마지막으로 주의해야할 점이 있다. 작업 증명 알고리즘은 작업 수행은 어렵지만 증명 검증은 쉬워야한다는 요구사항을 충족해야한다. 증명은 대개 다른 사람에게 넘어가기 때문에 검증 작업에 많은 시간이 소요되서는 안된다.
해싱
이 절에서는 해싱에 대해 다룰 것이다. 해싱이라는 개념에 익숙하다면 이 부분은 넘어가도 좋다.
해싱이란 어떤 특정한 데이터에 대한 해시를 얻는 과정이다. 해시란 계산된 데이터의 고유한 표현값이다. 해시 함수는 임의의 길이를 가진 데이터를 입력으로 받아 고정된 길이의 해시값을 생성하는 함수이다. 다음은 해싱의 핵심 기능이다.
- 원본 데이터는 해시에서 복원할 수 없다. 즉, 해싱은 암호화가 아니다.
- 특정 데이터는 단 하나의 해시값만 가지며 해시는 고유하다.
- 입력 데이터에서 하나의 바이트만 수정해도 완전히 다른 해시값이 생성된다.
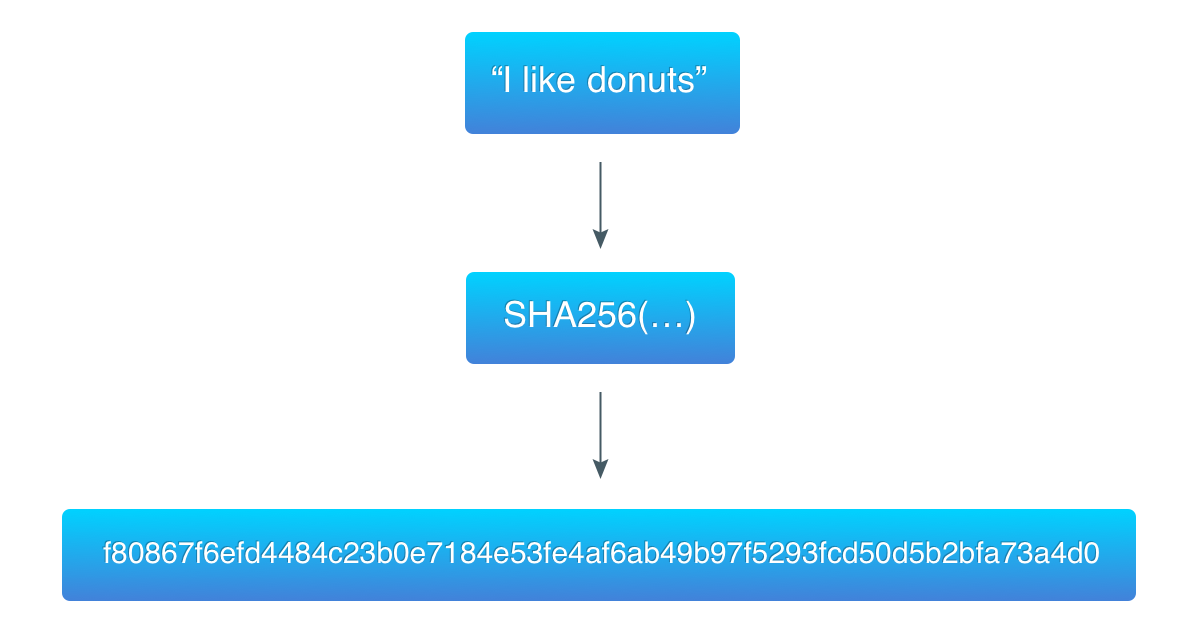
해시 함수는 데이터의 일관성을 검사하는데 널리 사용된다. 일부 소프트웨어 제공 업체는 소프트웨어 패키지와 함께 체크섬을 퍼블리싱한다. 파일을 다운로드한 후 이를 해싱 함수에 넣어 생성한 해시를 소프트웨어 개발자가 제공한 해시와 비교할 수 있다.
블록체인에서 해싱은 블록의 일관성을 보장하는데 사용된다. 해싱 알고리즘의 입력 데이터에는 이전 블록의 해시값도 포함되어 있기 때문에 체인상의 어떤 한 블록을 변경하는건 불가능하다 (또는 아주 어렵다). 하나의 블록을 변경하면 해당 블록에 대한 해시와 그 이후의 모든 블록들에 대한 해시를 다시 계산해야하기 때문이다.
해시캐시 (Hashcash)
비트코인은 초기에 이메일 스팸을 방지하기 위해 개발된 작업 증명 알고리즘인 해시캐시를 사용한다. 알고리즘은 다음 스텝들로 나눌 수 있다.
- 공개적으로 알려진 데이터를 가져온다 (이메일의 경우 수신자의 이메일 주소, 비트코인의 경우 블록의 헤더를 들 수 있다)
- 여기에 카운터를 더한다. 카운터는 0부터 시작한다.
- data + counter의 해시를 구한다.
- 해시가 특정 요구사항을 충족하는지 확인한다.
- 만족한다면 알고리즘을 끝낸다.
- 그렇지 않다면 카운터를 증가시켜 3번과 4번 스텝을 반복한다.
즉, 이는 무차별 대입 (Brute-force) 알고리즘으로 카운터를 늘리고 새로운 해시를 계산하고 검증하는 과정을 반복한다. 이게 바로 작업 증명의 계산 비용이 높은 이유이다.
이제 해시가 충족해야하는 요구사항이 무엇인지 자세히 살펴보도록 하자. 원래의 해시캐시 구현체에서의 요구사항은 “첫 20비트가 모두 0이어야함"이다. 비트코인의 요구사항은 종종 조정되는데, 시간이 지남에 따라 연산 능력이 증가하고 네트워크에 참여하는 채굴자들이 늘어남에도 불구하고 설계상 10분마다 하나의 블록이 생성되어야하기 때문이다.
알고리즘 시연을 위해, 이전 예제의 데이터 (“I like donuts”)를 가지고 3개의 제로 바이트로 시작하는 해시를 찾았다.
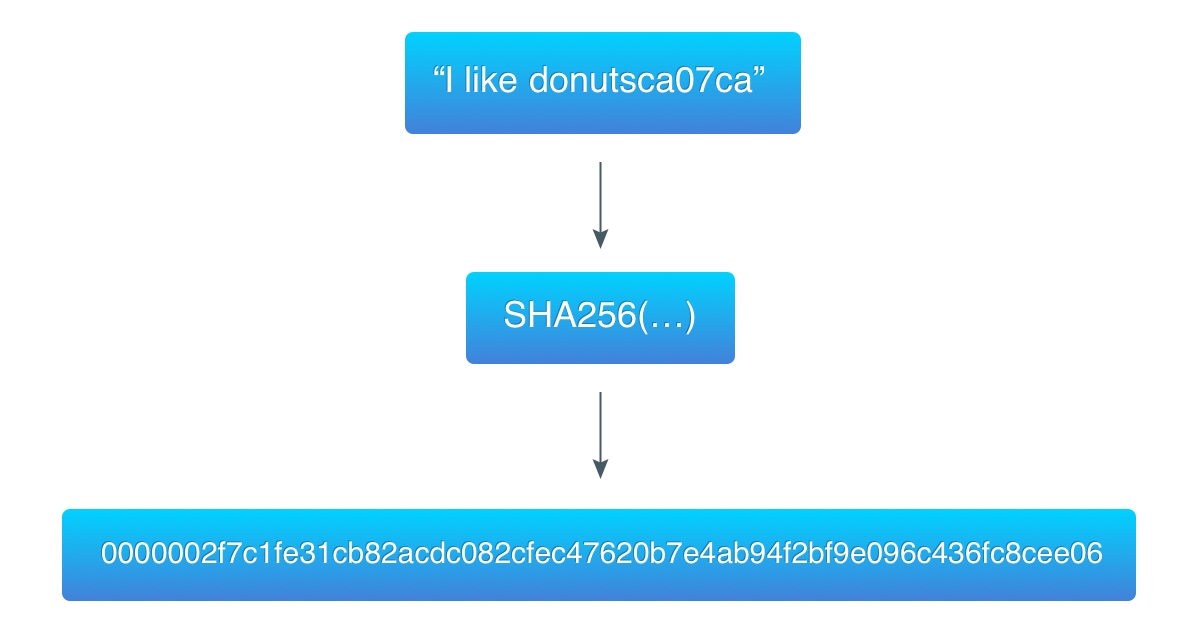
ca07ca는 10진수로 13240266인 카운터의 16진수값이다.
구현
이론은 다 살펴보았으니 이제 코드를 작성해보자! 먼저 채굴 난이도를 정의하자.
const targetBits = 24
비트코인에서 “목표 비트 (target bits)“란 블록이 채굴되는 난이도를 저장하고 있는 블록 헤더이다. 현재는 목표 조정 알고리즘을 구현하진 않을 것이므로 난이도를 전역 상수로 정의할 수 있다.
24는 임의의 숫자이고, 우리의 목표은 256비트 이하의 메모리를 차지하는 타겟을 갖는 것이다. 그리고 차이가 커질수록 적절한 해시를 찾는 것이 어려워지기 때문에 차이가 충분히 크지만 너무 크지는 않길 바란다.
type ProofOfWork struct {
block *Block
target *big.Int
}
func NewProofOfWork(b *Block) *ProofOfWork {
target := big.NewInt(1)
target.Lsh(target, uint(256-targetBits))
pow := &ProofOfWork{b, target}
return pow
}
블록 포인터와 타겟 포인터를 가진 ProofOfWork 구조체를 만들었다. “타겟 (target)“이란 이전절에서 언급했던 요구사항의 또 다른 말이다. 해시와 타겟을 비교할 수 있도록 큰 (Big) 정수를 사용했다. 우리는 해시를 큰 정수로 변환하여 이 값이 타겟보다 작은지 검사할 것이다.
NewProofOfWork 함수에서 bit.Int을 1로 초기화하고 256 - targetBits 비트만큼 좌측 시프트 연산을 취했다. 256은 SHA-256 해시의 비트 길이로 SHA-256이 우리가 사용할 해시 알고리즘이다. target의 16진수값은 다음과 같다.
0x10000000000000000000000000000000000000000000000000000000000
이 값은 메모리에서 29바이트를 차지한다. 이전 예제의 해시값을 가져와 시각적으로 비교해보자.
0fac49161af82ed938add1d8725835cc123a1a87b1b196488360e58d4bfb51e3
0000010000000000000000000000000000000000000000000000000000000000
0000008b0f41ec78bab747864db66bcb9fb89920ee75f43fdaaeb5544f7f76ca
첫 번째 해시값 (“I like donuts"의 해시)은 타겟보다 크기 때문에 유효한 작업 증명이 아니다. 두번째 해시값 (“I like donutsca07ca”)은 타겟보다 작기 때문에 유효한 증명이다.
그렇다면 이 타겟값을 유효 범위의 상한선으로 생각할 수 있다. 해시가 이 경계값보다 작으면 유효하고 그 역도 마찬가지이다. 경계값을 낮추면 유효한 해시값의 범위가 줄어들어 이 값을 찾는 작업이 더욱 어려워진다.
이제 해시 계산을 위한 데이터가 필요하므로 데이터를 준비하도록 하자.
func (pow *ProofOfWork) prepareData(nonce int) []byte {
data := bytes.Join(
[][]byte{
pow.block.PrevBlockHash,
pow.block.Data,
IntToHex(pow.block.Timestamp),
IntToHex(int64(targetBits)),
IntToHex(int64(nonce)),
},
[]byte{},
)
return data
}
단순히 블록의 필드값들과 타겟 및 논스값을 병합하는 직관적인 코드다. **논스 (nonce)**란 해시캐시에서의 카운터와 동일한 역할을 하는 암호학 용어이다.
모든 준비는 끝났다. 이제 PoW 알고리즘의 핵심 코드를 구현해보자.
func (pow *ProofOfWork) Run() (int, []byte) {
var hashInt big.Int
var hash [32]byte
nonce := 0
fmt.Printf("Mining the block containing \"%s\"\n", pow.block.Data)
for nonce < maxNonce {
data := pow.prepareData(nonce)
hash = sha256.Sum256(data)
fmt.Printf("\r%x", hash)
hashInt.SetBytes(hash[:])
if hashInt.Cmp(pow.target) == -1 {
break
} else {
nonce++
}
}
fmt.Print("\n\n")
return nonce, hash[:]
}
먼저 변수들을 초기화한다. hashInt는 hash의 정수 표현값이며 nonce는 카운터이다. 다음으로 “무한” 루프를 실행한다. 이는 최대 maxNonce만큼만 실행되며 이 값은 math.MaxInt64와 같다. 루프 횟수를 제한하는 이유는 nonce의 오버플로우를 막기 위해서이다. 물론 우리의 PoW 구현체의 난이도는 카운터가 오버플로우 나기에는 아주 낮지만 경우에 따라서는 오버플로우 검사를 하는게 더 좋다.
루프에서는 다음의 작업들이 수행된다.
- 데이터 준비 (생성)
- SHA-256 해싱
- 해시값의 큰 정수로의 변환
- 정수값과 타겟값 비교
이전에 설명된것처럼 쉽다. 우리는 이제 Block의 SetHash 메서드를 제거하고 NewBlock 함수를 수정할 수 있다.
func NewBlock(data string, prevBlockHash []byte) *Block {
block := &Block{time.Now().Unix(), []byte(data), prevBlockHash, []byte{}, 0}
pow := NewProofOfWork(block)
nonce, hash := pow.Run()
block.Hash = hash[:]
block.Nonce = nonce
return block
}
nonce가 Block의 프로퍼티로 저장되고 있음을 볼 수 있다. 증명 검증에 nonce가 필요하기 때문에 이는 필수적이다. Block 구조체는 이제 다음과 같이 작성할 수 있다.
type Block struct {
Timestamp int64
Data []byte
PrevBlockHash []byte
Hash []byte
Nonce int
}
완성되었다! 잘 동작하는지 확인하기 위해 한 번 실행해보자.
Mining the block containing "Genesis Block"
00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Mining the block containing "Send 1 BTC to Ivan"
00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Mining the block containing "Send 2 more BTC to Ivan"
000000b33185e927c9a989cc7d5aaaed739c56dad9fd9361dea558b9bfaf5fbe
Prev. hash:
Data: Genesis Block
Hash: 00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Prev. hash: 00000041662c5fc2883535dc19ba8a33ac993b535da9899e593ff98e1eda56a1
Data: Send 1 BTC to Ivan
Hash: 00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Prev. hash: 00000077a856e697c69833d9effb6bdad54c730a98d674f73c0b30020cc82804
Data: Send 2 more BTC to Ivan
Hash: 000000b33185e927c9a989cc7d5aaaed739c56dad9fd9361dea558b9bfaf5fbe
와우! 모든 해시가 3개의 제로 바이트로 시작하고 있음을 볼 수 있다. 또한 해시값들을 얻는데 일정 시간이 소요되었음을 확인할 수 있다.
마지막으로 할 일이 하나 남았다. 작업 증명을 검증할 수 있는 기능을 만들어보자.
func (pow *ProofOfWork) Validate() bool {
var hashInt big.Int
data := pow.prepareData(pow.block.Nonce)
hash := sha256.Sum256(data)
hashInt.SetBytes(hash[:])
isValid = hashInt.Cmp(pow.target) == -1
return isValid
}
위에서 저장한 논스는 바로 이 검증 로직에서 필요하다.
잘 동작하는지 한 번 더 확인해보자.
func main() {
...
for _, block := range bc.blocks {
...
pow := NewProofOfWork(block)
fmt.Printf("PoW: %s\n", strconv.FormatBool(pow.Validate()))
fmt.Println()
}
}
출력:
...
Prev. hash:
Data: Genesis Block
Hash: 00000093253acb814afb942e652a84a8f245069a67b5eaa709df8ac612075038
PoW: true
Prev. hash: 00000093253acb814afb942e652a84a8f245069a67b5eaa709df8ac612075038
Data: Send 1 BTC to Ivan
Hash: 0000003eeb3743ee42020e4a15262fd110a72823d804ce8e49643b5fd9d1062b
PoW: true
Prev. hash: 0000003eeb3743ee42020e4a15262fd110a72823d804ce8e49643b5fd9d1062b
Data: Send 2 more BTC to Ivan
Hash: 000000e42afddf57a3daa11b43b2e0923f23e894f96d1f24bfd9b8d2d494c57a
PoW: true
결론
우리의 블록체인은 실제 아키텍처에 한 발 더 가까이 다가갔다. 블록 생성은 이제 어려운 작업을 요구하고 있으며 채굴이 가능해졌다. 그러나 아직도 일부 중요한 기능들이 빠져있다. 블록체인 데이터베이스가 영구적이지 않으며 지갑, 주소, 트랜잭션 및 합의 메커니즘 또한 없다. 이 모든건 이후의 파트들을 통해 구현해 나갈 것이다.