[리뷰] DEVIEW : 쿠키런 AI 구현하기
Oct 26, 2016 00:00 · 5343 words · 11 minute read
사실 처음엔 데뷰 관련 리뷰를 딱히 작성할 생각이 없었기에 발표 사진을 하나도 찍지 않았습니다. 이 점에 대해선 양해바랍니다.
이 글에 나오는 이미지들은 모두 발표 슬라이드에서 가져왔습니다.
얼마전 24, 25일에 열린 DEVIEW 2016에 다녀왔다. 이틀 모두 참석하면서 들은 세션중 정말 유익하고 재밌게 들었던 세션들이 있는데, 그 중 특히 둘째날에 진행된 데브시스터즈 김태훈님의 딥러닝과 강화 학습으로 나보다 잘하는 쿠키런 AI 구현하기 DEVIEW 2016 세션이 기억에 남아 리뷰를 작성하려한다.
리뷰를 작성하기 전에 미리 말해둘게 있는데, 나는 이 글을 순전히 머신러닝에 관심이 있는 초보자의 입장에서 작성할 것이다. 나는 딥러닝을 포함한 머신러닝을 직접 다뤄본적이 없고, 해당 분야에 대한 지식도 별로 없기 때문이다. 아는거라곤 지도 학습(Supervised Learning)과 비지도 학습(Unsupervised Learning)에 대한 기본개념 정도가 끝이다. (여기서 지도 학습과 비지도 학습에 대해 다루지는 않겠다. 위에 링크가 걸려있으니 자세한 내용은 링크글을 읽기 바란다.) 근데 내가 알고있는 지도학습과 비지도학습으로 러닝 AI를 구현한다는건 전혀 상상이 가지않았다. 그래서 더욱 관심을 가진 세션이기도 하다.
이제 본론으로 들어가자.
우선 간단하게 해당 세션의 주제에 대해 말해보자면 제목 그대로 쿠키런 AI 구현에 대한 이야기이며, 쿠키런 AI (데브시스터즈에선 AlphaRun이라 부른다고한다)를 어떤 딥러닝 알고리즘을 적용하여 구현했는지와 어떻게 활용하고 있는지에 대한것이다.
발표의 앞부분은 간단한 AI의 의미와 예시에 대한 설명으로 채워졌고, 이후에 드디어 본격적으로 머신러닝과 딥러닝에 대한 설명으로 들어갔다. (이럴 때 사진이 있었으면 참 좋았을텐데 .. 이제와서 후회중)
적용한 딥러닝 알고리즘을 설명하기전에 머신러닝에 어떤 학습 방법들이 있는지에 대해서 설명해주셨다. 크게 총 3가지가 있었다. 그 중 두 개는 위에서도 언급했던 지도 학습과 비지도 학습이었고, 나머지 하나는 강화 학습(Reinforcement Learning)이라고 하는 학습 방법이었다. 그리고 쿠키런 AI에는 바로 이 강화 학습이 적용되었다고 한다. 그렇다. 내가 기존에 알고 있던 지도/비지도 학습을 사용하는게 아니었다. 그렇다면 강화 학습이란 무엇일까?
강화 학습(Reinforcement Learning) 이란, 간단히 말하면 어떤 에이전트가 특정한 환경에서 현재 상태를 기반으로 다음에 선택 가능한 행동들중 보상을 최대화 시킬 수 있는 행동을 택하면서 학습하는 방법이다.
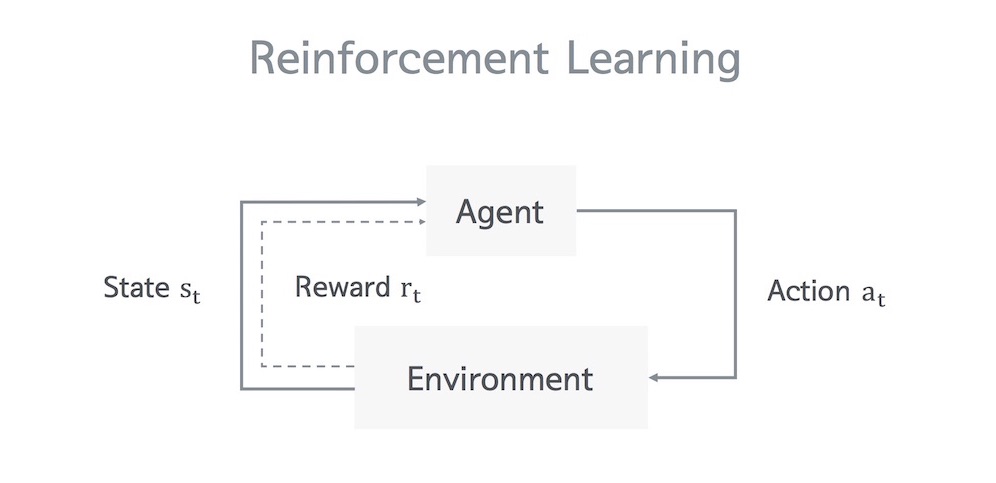
다음은 실제 쿠키런에서의 강화 학습을 나타낸 그림이다.
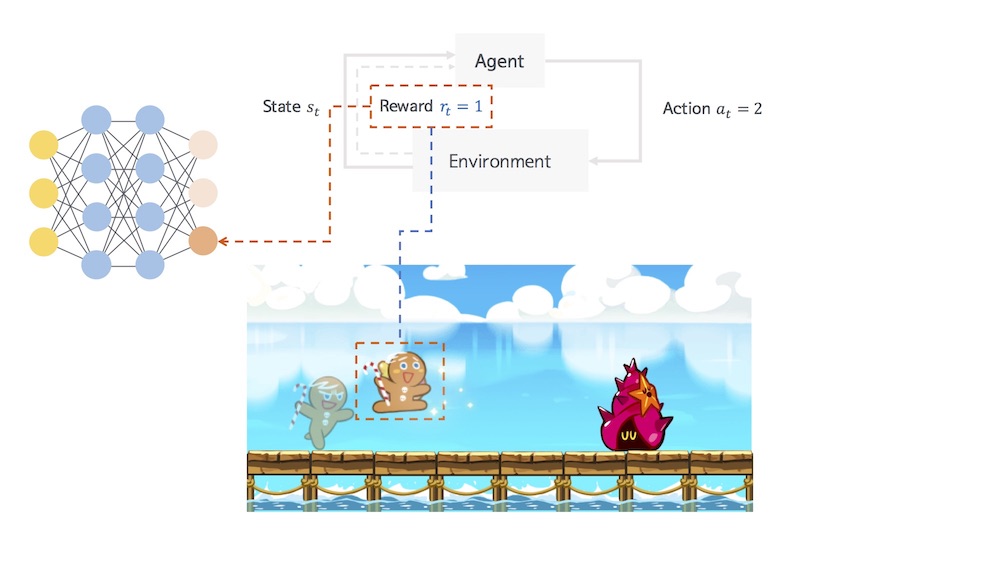 다음 상황에서 적절한 행동을 했을 경우 긍정적인 보상을 받으며 학습된다.
다음 상황에서 적절한 행동을 했을 경우 긍정적인 보상을 받으며 학습된다.
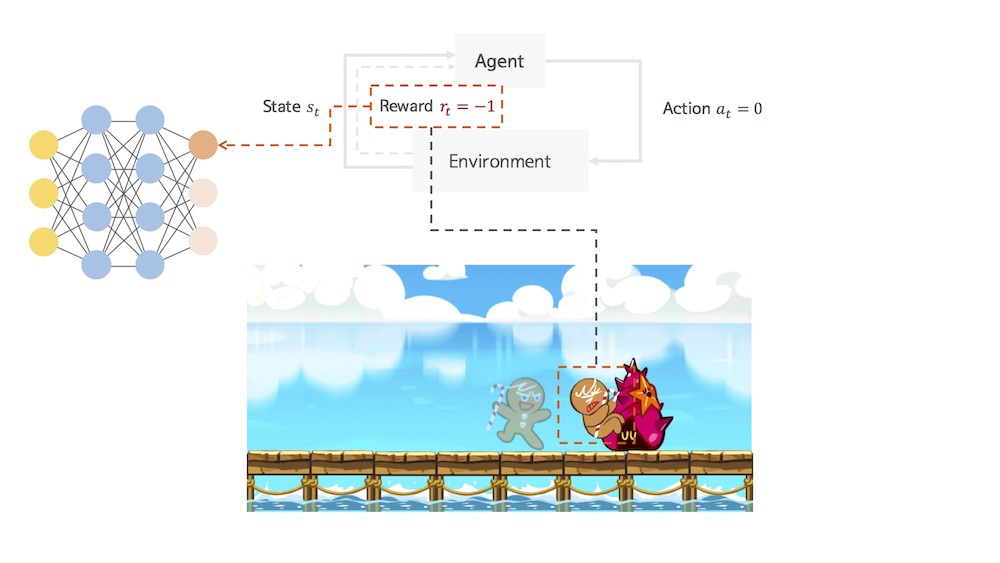 다음 상황에서 적절하지 않은 행동을 했을 경우 부정적인 보상을 받으며 학습된다.
다음 상황에서 적절하지 않은 행동을 했을 경우 부정적인 보상을 받으며 학습된다.
Environment에 있는 Agent의 현재 상태 $$ s_t $$에서 $$ a_t $$라는 행동을 취할 때의 보상인 $$ r_t $$ 의 값을 가지고 학습을 시키고 있음을 볼 수 있다. 이처럼 현재 상태를 기반으로 다음 행동들에 대한 보상값들을 피드백으로 받으며 계속 학습해나가는 방법이 바로 강화 학습이다. 조금 더 생각해보면 이는 우리가 실제로 게임을 하는 과정과 매우 닮아있다. 인지는 못하지만 실제로 우리는 게임을 할 때 캐릭터 앞에 있는 장애물이나 아이템을 보며 매번 최선의 선택을 하면서 게임을 한다. 우리가 실제로 게임을 하는 과정을 스스로 이해할 수 있다면 강화 학습이란걸 조금 더 이해하기 쉬울 것이다.
강화 학습을 설명한 후에는 AlphaRun이 어디에 쓰일 수 있는지를 설명해주셨는데, 이 부분은 조금 나중에 말하려고한다. 그럼 바로 AlphaRun에 적용된 딥러닝 알고리즘에 대한 기술을 살펴보겠다.
AlphaRun에는 총 8가지의 딥러닝 + 강화 학습 기술이 적용되었다고 한다. 나는 조금 놀랐다. 사실 겉으로만 봤을 때는 그렇게 복잡할 것 같지는 않았지만 막상 이걸 실제 개발과 구현의 관점에서 들여다보니 그렇지 않았다. 게다가 두세 개도 아니고 무려 8개나 쓰인다니! 물론, 아쉽게도 발표 시간의 제한때문에 이 8가지의 모든 알고리즘을 다루진 않았다. 모두 다뤘어도 이해 못했을 것 같다
AlphaRun에 적용된 8가지의 알고리즘은 다음과 같으며 이 중 앞의 3가지를 설명해주셨다. 참고로 1 ~ 6의 알고리즘은 DeepMind에서 개발한 알고리즘이라고 한다.
- Deep Q-Network
- Double Q-Learning
- Dueling Network
- Prioritized Experience Relay
- Model-free Episodic Control
- Asynchronous Advantageous Actor-Critic method
- Human Checkpoint Replay
- Gradient Descent with Restart
나는 해당 알고리즘의 원 논문을 본 적이 없기 때문에 알고리즘의 상세한 내용들은 설명하지 않을 것이다. (사실 못한다.) 따라서 세션에서 들었던 내용을 기반으로 알고리즘이 어떻게 돌아가는지 정도만 설명하려고 한다. 다음에 기회가 된다면 각 알고리즘의 논문을 직접 읽고 공부한 뒤 상세한 설명 및 구현을 포스팅 해보겠다.
이제 1 ~ 3의 각 알고리즘을 발표 내용과 함께 살펴보겠다.
Deep Q-Network
AlphaRun에서는 상태 $$ s_t $$와 행동 $$ a_t $$를 다음과 같은 행렬과 값으로 나타낸다.
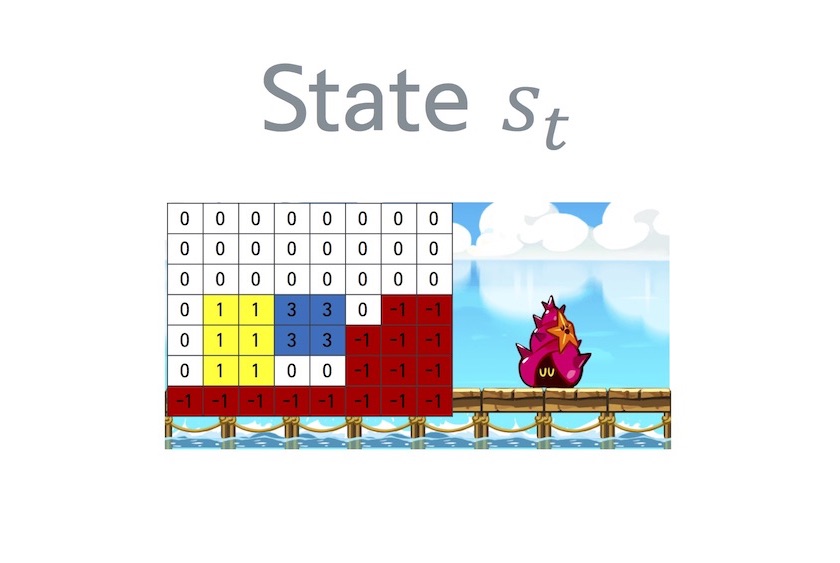
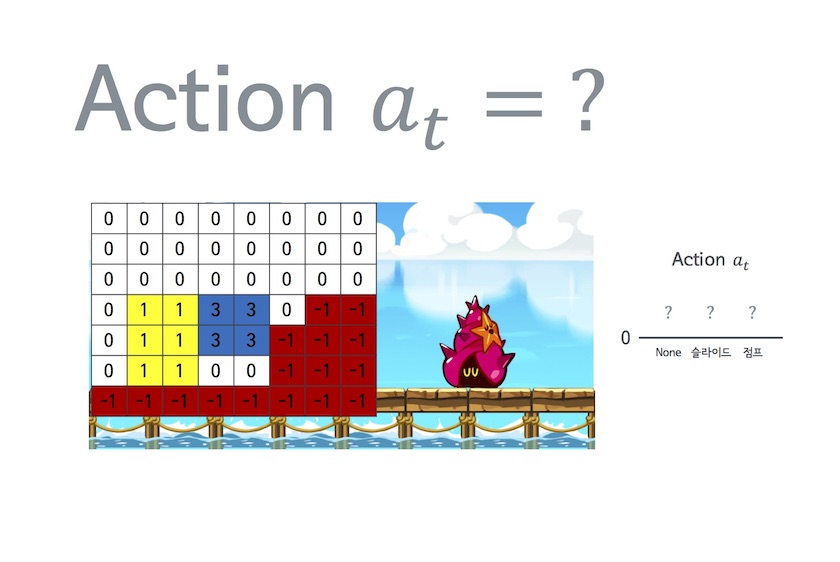
그리고 $$ Q $$라는 함수를 $$ s $$에서 $$ a $$를 했을 때의 ‘기대 미래가치'라고 정의한다. 즉, AlphaRun에서는 다음과 같은 그림으로 표현할 수 있다. 이 경우 ‘슬라이드'에 대한 ‘기대 미래가치'가 5로서 가장 크기 때문에 다음 행동은 ‘슬라이드'로 행하는게 좋다는걸 알 수 있다. 참고로 쿠키런에서의 ‘가치'란 바로 ‘점수'를 뜻한다. 즉 $$ Q $$는 미래에 얻을 점수의 합을 의미한다.
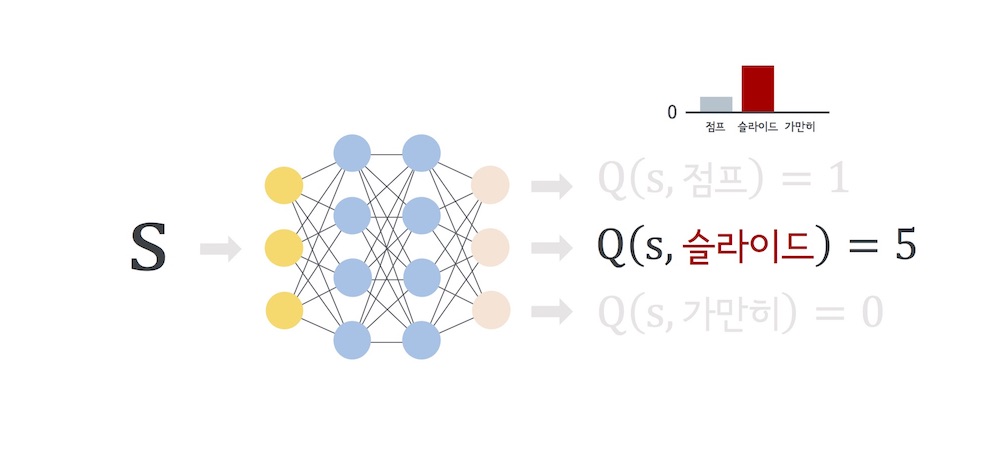
실제 게임에서의 예를 들면 다음과 같다.
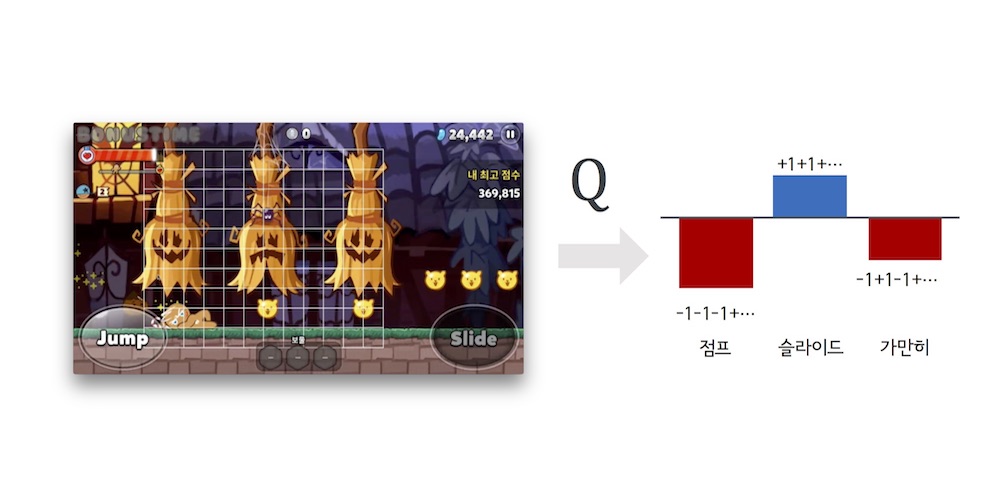
직관적으로도 당연히 슬라이드를 해야하는 상황이다. 이걸 $$ Q $$의 관점에서 보면 슬라이드를 할 경우의 점수가 점프와 가만히 있을때의 그것보다 ‘가치'값이 높기때문에 AlphaRun은 슬라이드를 택할 것이다.
이 Q-Learning의 squared error loss는 다음과 같다. $$ a’ $$는 가능한 모든 행동들이다.
$$ loss = (Q(s,a) - (r + {\gamma}max_{a’}\hat{Q}(s,a’)))^2 $$
이 $$ loss $$를 가지고 loss function $$ L $$을 정의하고 이를 최소화 함으로써 학습시킬 수 있다.
이렇게 Q-Learning 알고리즘만 적용한 AlphaRun의 영상을 보여주셨다. 어느 정도 잘 돌아가는 것처럼 보였다. 그러나 몇몇 상황에서는 쿠키가 이상한 행동을 하였으며, 따라서 이를 개선하기 위해 Double Q-Learning 알고리즘을 적용하였다고 한다.
Double Q-Learning
$$ Q $$값이 낙관적인 예측을 하거나 발산하는걸 막기위해 사용된 알고리즘이다. Deep Q-Network에서는 $$ loss $$값은 낮아지는데 예측값($$ Q(s, a) $$)과 정답값($$ r + {\gamma}max_{a’}\hat{Q}(s,a’) $$)이 계속 커지는 일이 발생할 수 있다. 따라서, 이를 막기위해 Double Q-Learning에서는 $$ loss $$를 다음과 같이 정의한다.
$$ loss = (Q(s,a) - (r + {\gamma}\hat{Q}(s,{\arg} max_{a’}Q(s,a’))))^2 $$
Double Q-Learning에 대한 이론적인 내용은 사실 잘 몰라서 자세한 설명을 못할 것 같다. 대신 논문 링크를 남기겠다. Double Q-Learning
아무튼 결론적으로는 Deep Q-Network를 사용했을때보단 점수가 높아진걸 볼 수 있었다. 실제로 쿠키도 Deep Q-Network를 적용했을때 나타났던 이상한 행동도 사라진 걸 볼 수 있었다.
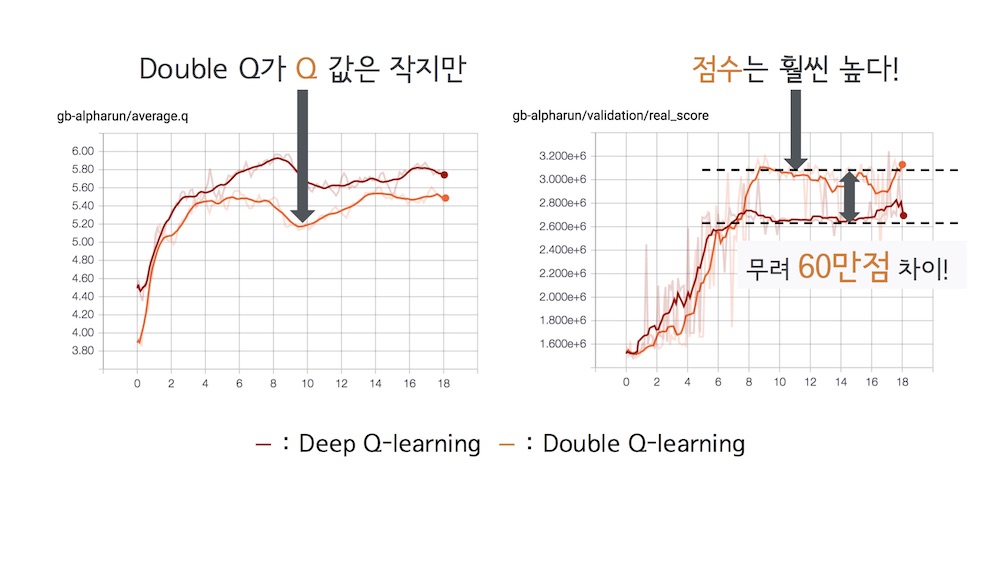
Double Q-Learning을 적용한 AlphaRun은 단순한 맵에서는 잘 동작했지만, 움직이는 발판이나 장애물이 있는 맵에서는 그다지 효율이 좋지 못했다. 특히 보너스 타임의 경우 쿠키가 위로만 쭉 올라가는 영상을 보여주며 큰 웃음을 선사해주셨다. 하하
이러한 문제를 개선하기위해 다른 알고리즘을 적용하여 개선작업을 계속해나갔다. 다음으로 적용한 알고리즘은 Dueling Network 알고리즘이다.
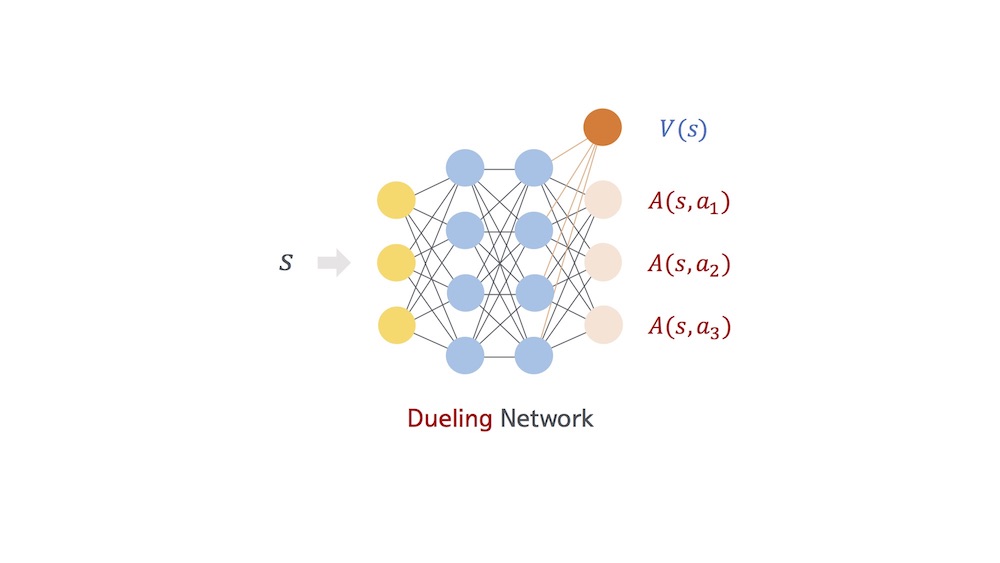
Dueling Network
Dueling Network 알고리즘을 사용하게된 배경은 쿠키 앞에 젤리가 많은지 장애물이 많은지 전혀 알 수가 없어 정확한 $$ Q $$값을 예측하는게 어렵다는 것이다. 데브시스터즈 개발팀은 과연 $$ Q $$값을 정확하게 예측할 필요가 있나라는 의문을 가지며 다른 방법으로 이 문제에 접근했다고 한다. 결국은 값을 정확하게 예측하지않고, 어떤 값을 기준으로한 상대적인 값을 예측하기로 했다. 만약에 슬라이드가 $$ x $$라면 점프는 $$ x + 3 $$, 가만히는 $$ x + 1 $$이 되는 식이다.
즉, $$ Q $$를 다음과 같이 쓸 수 있게된다.
$$ Q(s,a) =V(s) + A(s,a) $$
$$ V(s) $$는 Value의 의미로 기준점 $$ x $$를 뜻하고, $$ A(s,a) $$는 Advantage의 의미로 상대적인 Q값의 차이를 뜻한다.
또한, 따라서 Dueling Network는 다음 그림처럼 표현할 수 있게된다. 그림에서 $$ V $$와 $$ A $$의 합이 $$ Q $$가 된다.
위 식에서 Advantage인 $$ A(s,a) $$부분은 주어진 $$ Q $$로부터 $$ V $$와 $$ A $$를 복구 가능하게 해 성능을 높일 수 있도록 변형을 가할 수 있는데 종류로는 Max와 Average가 있다. 기존의 식인 Sum을 포함하면 다음 세 가지의 경우가 있다.
$$ Sum : Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta) + A(s,a;\theta,\alpha)$$
$$ Max : Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta) + (A(s,a;\theta,\alpha)-max_{a’{\in}𝒜}A(s,a;\theta,\alpha))$$
$$ Average : Q(s,a;\theta,\alpha,\beta) = V(s;\theta,\beta) + (A(s,a;\theta,\alpha)-\frac{1}{|𝒜|}{\Sigma}_{a’}A(s,a;\theta,\alpha))$$
Dueling Network를 적용한 후에는 다음과 같은 성능 향상을 얻을 수 있었다고한다.
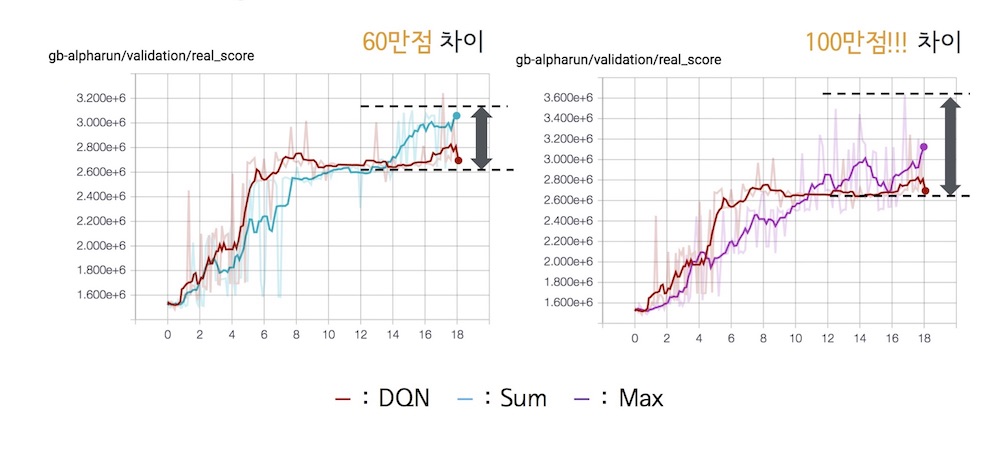
Dueling Network를 끝으로 AlphaRun에 적용된 세 가지 딥러닝 알고리즘에 대한 소개가 끝났다. 대략의 원리는 이해가 갔지만, 아무래도 딥러닝이란걸 해본 적이 없어서 그런지 완전히 이해하기에는 한계가 있었다. 특히, Dueling Network에 나온 수식과 같은 식은 처음보는 형태라 이해가 어려웠다. 그래도 이렇게나마 간접적으로 딥러닝을 체험하고, 딥러닝이란게 어떻게 동작하고 사용되는지에 대해 아주 조금은 이해할 수 있었다.
이 후에는 AlphaRun 개발을 하며 겪었던 다음과 같은 주제들에 대해서도 경험기를 소개해주셨다.
- Hyperparameter tuning : 말 그대로 파라미터 튜닝에 관한 얘기였으며 딥러닝 실험에 관한 얘기를 들려주셨다. AlphaRun에만 파라미터가 약 70개나 존재했는데, 이런 경우 어떻게 튜닝을 진행하는지에 대한 내용이다. 결론은 실험이다 .. 튜닝은 사실 실험밖에 답이 없기때문에, 변수 고정과 같은 실험 과정에 대한 최적화가 필요하다고 얘기하셨다. 자세한건 영상과 슬라이드를 보면 될 것 같다.
- Debugging : 나도 사실 이 부분이 정말 궁금했다. 딥러닝을 돌리면서 각 레이어에서 어떤일이 벌어지고 그걸 어떻게 추적하는지가 정말 궁금했었는데 마침 관련 내용을 말씀해주셨다. 사실 이 세션을 듣기 전에 이미 본 적이 있었다. 바로 코엑스에서 진행된 쿠키런 AI와 대결하는 이벤트를 진행한 데브시스터즈 부스의 모니터에서 말이다. 물론 세션들 들으러 가느라 제대로 못봐서 뭔지도 몰랐다. 디버깅 툴이었다니. 본론으로 돌아가면, AlphaRun은 쿠키가 이동하는 행적들을 콘솔에서 보여주면서 디버깅을 하는 방식을 택했다. 즉, 쿠키가 이동하는 모습을 실시간으로 콘솔로 띄워 보면서 잘못된 부분을 찾는 방식이었다. 유레카! 어쩌면 당연한 방법일지도 모르지만 되게 신박한 방법인 것 같다. 실제로 이 디버깅 툴로 여러 문제를 해결한 사례를 말씀해주셨는데, 값을 실시간으로 볼 수 있다는게 큰 도움이 되었던 사례였다. 속으로 ‘오~'를 외쳤다.
- Pretrained model : 학습 시간을 단축시키는 팁이었는데, 모든 네트워크의 weight값을 저장한 뒤, 새로운 실험시 비슷한 실험의 weight를 처음부터 사용하는 방식이었다. 이 경우 처음부터 학습할 필요가 없기때문에 나중엔 더 높은 점수를 얻을 확률이 높아지게된다.
- Ensemble methods : 하나의 실험에서 만들어진 여러 weight값들을 동시에 로드하여 특정 상황별로 다른 weight를 적용해 성능을 높이는 방식이다. 예를 들면, 보너스 타임을 잘하는 weight와 젤리를 잘 먹는 weight가 있을 때 각 상황마다 다른 weight를 적용하는 식이다. 굉장히 유용한 방법인 것 같다.
마지막으로는 AlphaRun으로 수행한 밸런싱 자동화에 대한 그래프를 보여주셨다. 어 그런데 밸런싱 자동화라니? 아까 초반에 이 AI가 어디에 쓰이는지에 대해선 나중에 말한다고 했었는데 그게 바로 밸런싱 자동화이다.
밸런싱에 대해선 말 안해도 알 것 같다. 가끔 공지되는 밸런스 패치 업데이트가 바로 그것이다. 나도 쿠키런 유저이지만, 가끔 새로운 쿠키가 나오거나 하면 기존 쿠키와의 밸런스가 안맞아 점수차가 크게 벌어지는 경우가 있다. 물론 데브시스터즈에서도 QA팀에서 테스트를 진행 했겠지만, 아무래도 가능한 조합이 쿠키 x 펫 x 보물 x 맵의 수만큼 존재하기 때문에 수작업으로 모든 경우의 수를 테스트하는건 거의 불가능할 것이다. 발표 슬라이드에도 나왔듯이 쿠키 x 펫 x 보물 x 맵 = 30 x 30 x 9 x 7가지의 경우의 수가 존재하며, 여기에 판당 평균 플레이 시간(4분)을 곱하면 전체 테스팅에 약 5040일이 소요된다고 한다. 하지만 이 작업들을 모두 AI가 할 수 있다면, 그것도 매우 빠른 속도로 할 수 있다면 밸런싱 패치를 거의 완전히 자동화 시킬 수 있을 것이다. AI도 결국 프로그램이기 때문에 자체적으로 프레임을 높여도 플레이에는 전혀 지장이 없다. (사람이라면 못한다.) 즉, 게임 속도를 매우 빠르게 할 수 있으며, 이걸 다수의 프로세스가 돌리게 되면 위 조합들에 대해 약 14일밖에 걸리지 않는다. 360배 빨라진 셈이다. 다음은 실제 데브시스터즈에서 AI를 돌려 얻은 데이터이다.
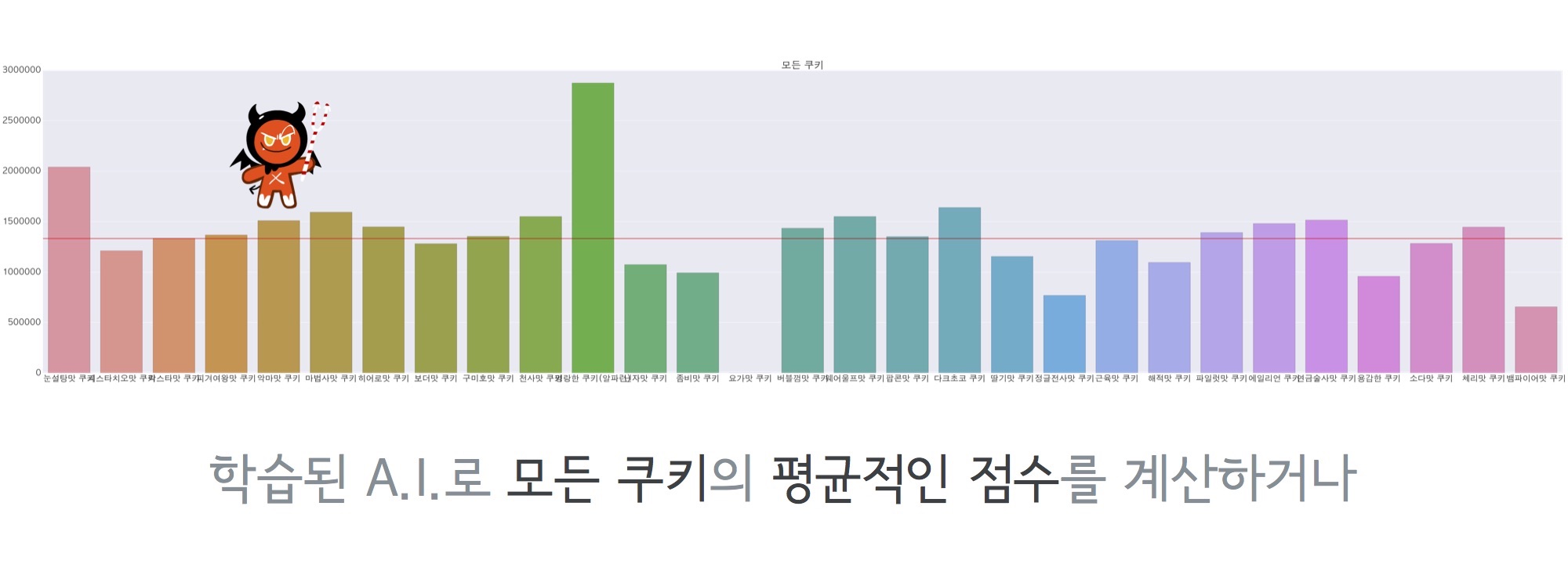 AlphaRun으로 돌린 모든 쿠키의 평균 점수
AlphaRun으로 돌린 모든 쿠키의 평균 점수
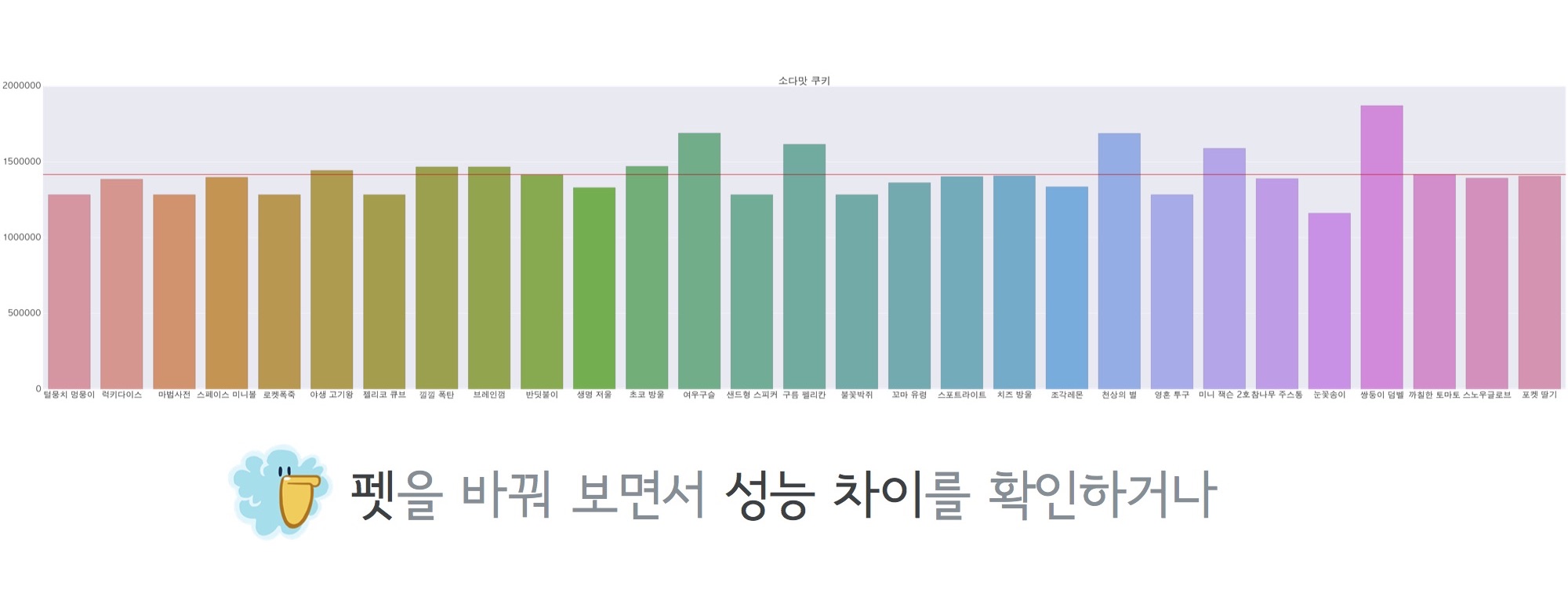 소다맛 쿠키 + 모든 펫 조합으로 돌린 성능차 그래프
소다맛 쿠키 + 모든 펫 조합으로 돌린 성능차 그래프
나는 그냥 AI라고 해서 단순히 게임 자동화 및 점수 향상에 대해서만 생각했었는데, 밸런싱 패치를 자동화 하는데에도 쓰일 수 있다니 .. 이렇게도 접근할 수 있구나하는 생각이 들었다.
아무쪼록 정말 유익하고 재밌게 들은 세션이었다. 아주 최근에 머신러닝 공부를 하기 시작했는데, 그래서 그런지 동기부여도 많이 되었고, 이것 저것 얻는게 많았던 것 같다. 물론 그게 기술적인 부분은 아니더라도 딥러닝 관련 알고리즘의 아이디어가 될 수도 있고, AI의 활용에 대한 아이디어가 될 수도 있다. 나중엔 나도 머신러닝으로 무언갈 구현하고 발표를 해보고싶다. 그 때 까지 열심히 해야겠다.
결론은 머신러닝 공부 열심히 하자! 수학 공부도 해야지, 논문도 보고, 책도 읽고…